|
I'm a CS PhD student at EPFL 🇨🇭 in the NLP group, where I'm supervised by Prof. Antoine Bosselut. I received the M.S. degree from the School of Engineering at EPFL 🇨🇭 in March 2024, specializing in Automatic and Systems. Previously, I completed my master thesis at TML lab, EPFL, supervised by Prof. Nicolas Flammarion, and will continue my research at TML lab as a research assistant. During my master studies, I was also fortunate to spend time as a semester project student at VITA lab, EPFL, supervised by Prof. Alexandre Alahi. I got my bachelor's degree from Zhejiang University 🇨🇳. My research focuses on enhancing the efficiency of training and deploying advanced AI models while ensuring robustness, generalization performance, and safety. I'm interested in developing tools to understand the fundamental capabilities of LLMs and leveraging the insights I get to improve the efficiency and reliability of LLM alignment. For pronunciation, my full name /how-jow/, but just my first name would be lot easier :) Google Scholar / Email / Twitter / Github / LinkedIn |

|
|
[Sep 18, 2025] One work on Benchmarking AI Agent Safety was accepted to NeurIPS 2025 as a Spotlight! [Jan 23, 2025] One work on Many-Shot ICL Alignment was accepted to ICLR 2025. [May 02, 2024] One work on data selection for Instruction Fine-Tuning LLMs was accepted to ICML 2024. [Jan 16, 2024] One work on Parameter-efficient Fine-tuning was accepted to ICLR 2024. [Apr 25, 2023] One work on Test-time Adaptation was accepted to ICML 2023. |
|
(* denotes equal contribution) |
|
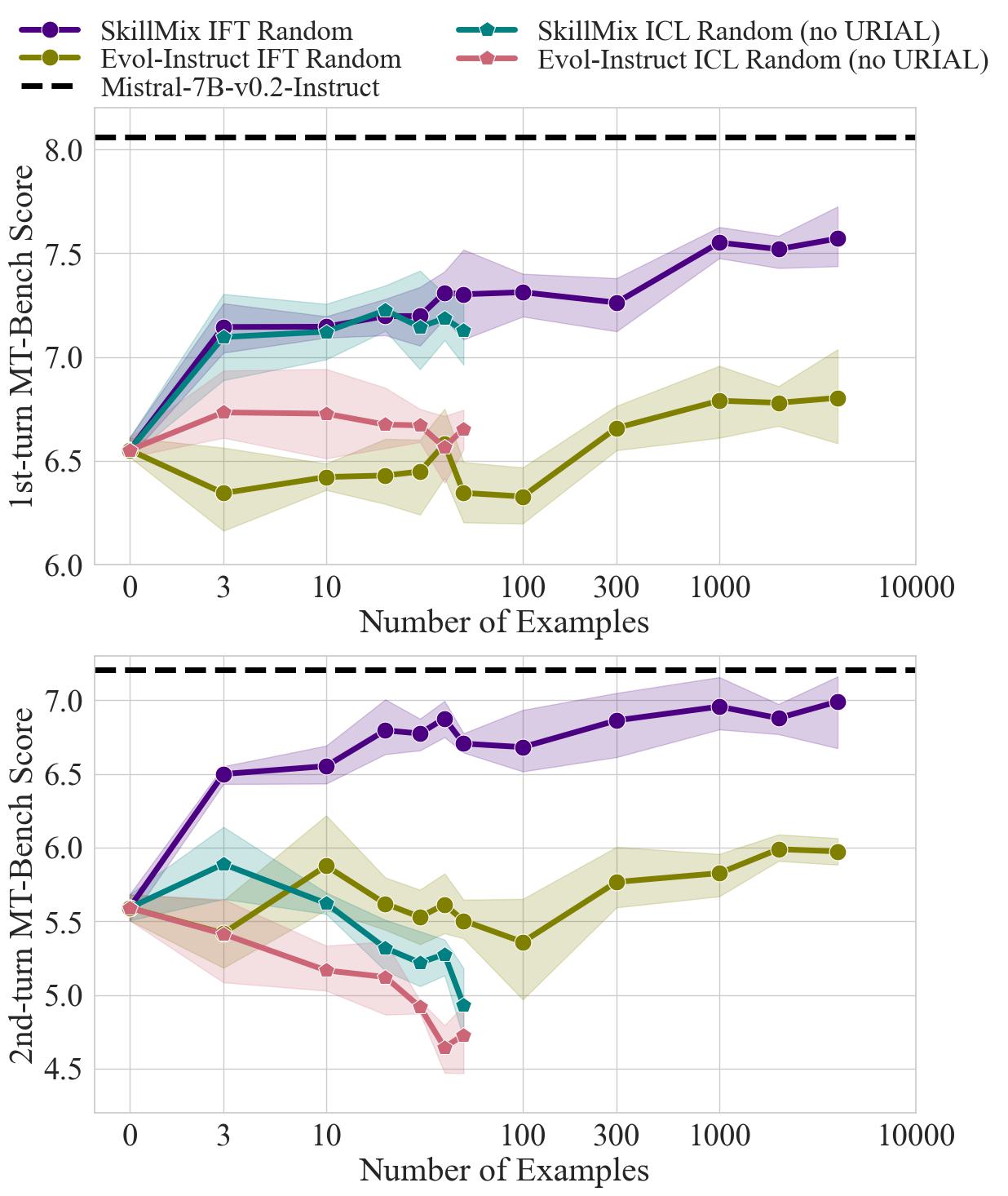
Hao Zhao, Maksym Andriushchenko, Francesco Croce, Nicolas Flammarion ICLR 2025, abridged in Workshop AFM@NeurIPS'24 [arXiv] [Code] [MIT Tech Review China] In this work, we show that, while effective, ICL alignment with URIAL (Lin et al., 2024) still underperforms compared to instruction fine-tuning on the established benchmark MT-Bench, especially with more capable base LLMs, such as GPT-4-Base. We then uncover the most relevant elements for successful in-context alignment, finding the crucial role of the decoding parameters. Based on these insights, we show that the approach of URIAL can indeed be improved by adding high-quality, possibly carefully selected via greedy search, demonstrations in context, getting closer to the performance of instruct models. Finally, we provide the first, to our knowledge, systematic comparison of ICL and instruction fine-tuning (IFT) for instruction following in the low data regime, where ICL can be a viable alternative to IFT. |
|
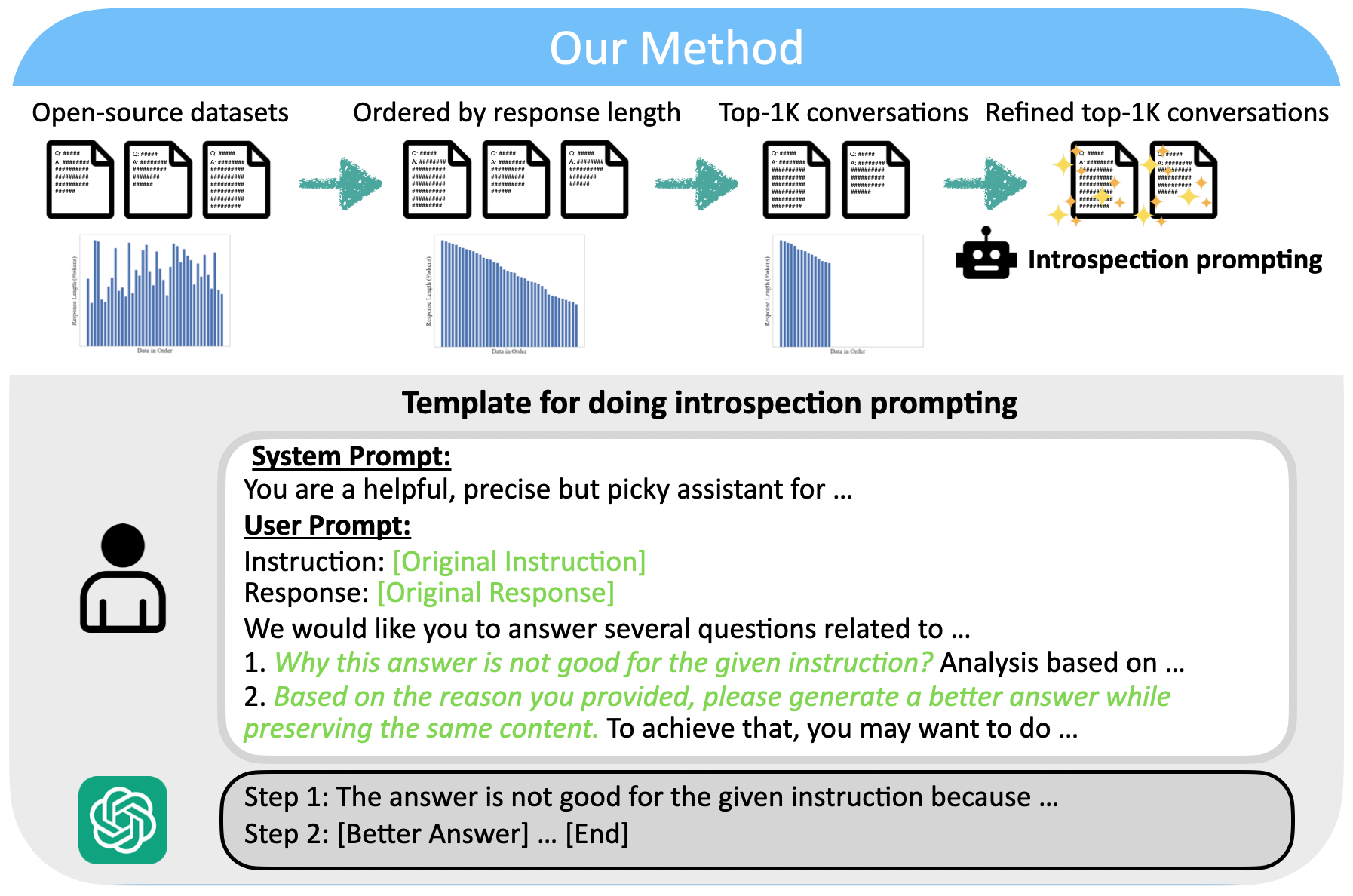
Hao Zhao, Maksym Andriushchenko, Francesco Croce, Nicolas Flammarion ICML 2024, abridged in Workshop DMLR@ICLR'24 [arXiv] [HuggingFace] [Code] Prior works demonstrate that instruction fine-tuning (IFT) of base LLMs over multi-million-example datasets enables them to fluently interact with human users. We show that filtering via length heuristics is an effective and efficient approach to select instruction tuning data for alignment, and find that fine-tuning on 1K instructions with the longest responses from large-scale IFT datasets, such as Alpaca, outperforms fine-tuning on full datasets. It validates the Superficial Alignment Hypothesis, which suggests that very few samples are sufficient to teach base LLMs to follow natural language instructions. In addition, we propose to refine pre-selected examples using GPT-4-Turbo, based on its exceptional judging and introspecting capabilities. The resulting dataset, consisting of only 1K instruction-response pairs, yielded competitive results on AlpacaEval 2.0 and MT-Bench compared to complex alignment approaches like RLHF and DPO. |
|
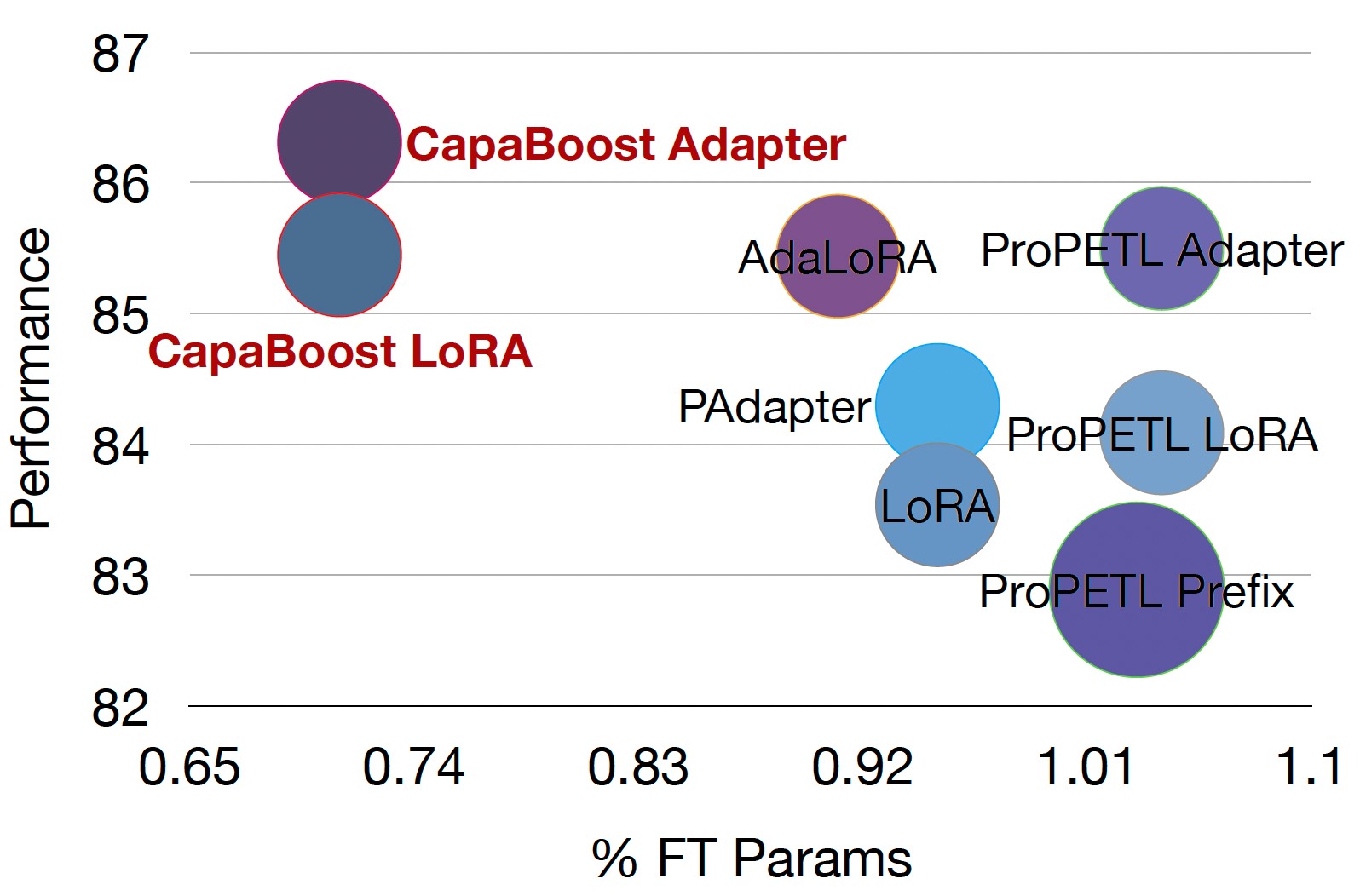
Haobo Song*, Hao Zhao*, Soumajit Majumder, Tao Lin ICLR 2024 [arXiv] [Code] The core idea of Parameter-Efficient Fine-Tuning (PEFT) methods, such as LoRA, is to model the incremental update of pre-trained weights (ΔW) through low-rank weight approximations, BA, where A and B are trainable weight matrices. While the compact dimensions of A and B offer notable parameter efficiency benefits, they also impose significant constraints on model capacity due to the inherent low-rank nature of their product. In this work, we propose CapaBoost, an effective plug-and-play approach, improving the performance of mainstream PEFT methods without increasing trainable parameters. By applying static random masks to the shared weight matrix, CapaBoost constructs a diverse set of weight matrices placed in parallel, effectively increasing the rank of incremental weights without adding new parameters. We extensively validate the efficacy of CapaBoost through experiments on various downstream tasks, including natural language understanding, question answering, and image classification. |
|
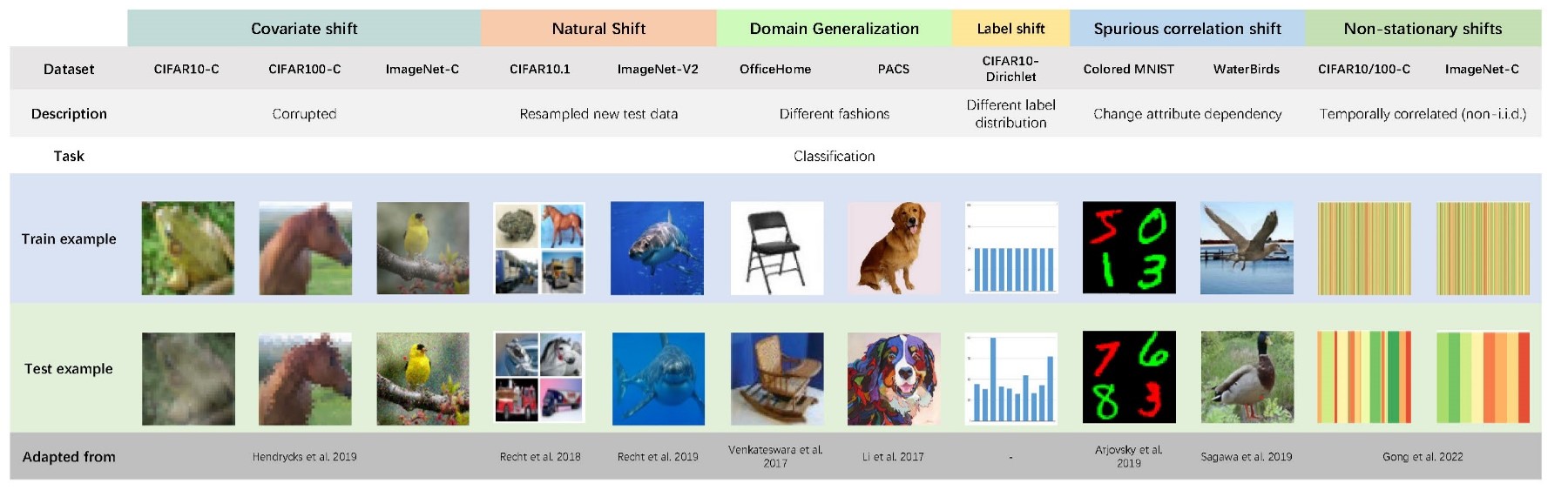
Hao Zhao*, Yuejiang Liu*, Alexandre Alahi, Tao Lin ICML 2023, abridged in Workshop DG@ICLR'23 (Spotlight) [arXiv] [Code] Test-Time Adaptation (TTA) has recently emerged as a promising approach for tackling the robustness challenge under distribution shifts. We present TTAB, a TTA benchmark that captures a wide spectrum of realistic settings, encompassing ten state-of-the-art algorithms, a diverse array of distribution shifts, and two evaluation protocols. With this benchmark, we conduct rigorous and holistic evaluations of how existing TTA algorithms perform on a broad set of models and distribution shifts, revealing three primary pitfalls that challenge the feasibility and effectiveness of current unsupervised learning paradigms in more realistic situations. |
|
[2021.9 - 2024.3] M.S. in Automatic and Systems, EPFL, Switzerland [2017.9 - 2021.6] B.Eng. in Mechanical Engineering, Zhejiang University, China |
|
Conferences: ICLR'25 Workshops: FITML@NeurIPS'24, ICL@ICML'24, WANT@ICML'24, DMLR@ICLR'24 |
|
When I'm not working, I enjoy strength training 🏋, hiking 🏃, and swimming 🏊. |
|
I borrowed this website layout from here! |